

Dans notre article précédent sur ce sujet (Partie 1), nous avons passé en revue les principaux types de contrats de fournisseurs de services gérés (MSP) (surveillance, opérationnel, optimisation, transformation), les attentes communes des MSP dans l’économie actuelle, et l’importance de définir des attentes claires comme base d’une relation fournisseur-client MSP saine.
L’article précédent portait sur l’information sur ce que sont les services gérés (MS) ou non, selon le type de contrat, pour servir de référence afin de mettre en lumière les avantages que les MSP peuvent apporter à l’entreprise et aux TI. Dans cet article, nous passerons en revue les défis typiques et les avantages que les MSP peuvent offrir pour y remédier, et dans de futurs articles de la série, nous examinerons les indicateurs que les clients peuvent utiliser pour comprendre s’ils tirent le plus de valeur d’un engagement MSP, et comment les MSP peuvent interpréter les signaux non exprimés pour savoir s’ils font un bon travail.
Défis courants dans l’économie actuelle
Commençons par mettre en lumière quelques défis courants auxquels de nombreuses organisations font généralement face. Dans l’économie actuelle, la plupart des décisions reposent sur une justification financière où les résultats d’un projet devraient avoir une ligne de vue directe vers l’augmentation des revenus et/ou la diminution des dépenses; cela rend très difficile pour les TI de financer des projets d’infrastructure, comme une mise à niveau complète d’Active Directory (AD) ou une mise à niveau généralisée des systèmes d’exploitation (OS) serveurs. Dans notre article précédent, nous avons abordé le manque chronique de personnel en TI, où trop peu de ressources informatiques sont disponibles pour gérer les projets d’affaires, ce qui oblige souvent les groupes d’affaires à agir de façon indépendante, ce qui produit souvent involontairement des résultats myopes. Parfois, l’organisation informatique d’une entreprise ne possède pas les compétences internes appropriées pour les technologies plus récentes; combiné à un financement informatique plus faible (pour la formation, la mise à niveau des infrastructures, etc.), cela entraîne souvent des technologies plus anciennes qui restent en place au-delà de leur durée de vie prévue. Beaucoup d’entreprises surveillent l’infrastructure informatique mais ne surveillent pas correctement l’expérience de l’utilisateur final, de sorte que dans trop de cas, les alertes en arrière-plan n’indiquent pas qu’il y a des problèmes, mais que les utilisateurs finaux subissent une dégradation de performance ou possiblement des perturbations de service, sans que l’informatique ne soit informée jusqu’à ce que les utilisateurs signalent des problèmes.
Ces défis influencent la perception des dirigeants d’entreprise selon laquelle les TI ne peuvent pas répondre aux besoins d’affaires en temps opportun, que les TI ne fournissent pas de solutions précises et/ou que les TI ne sont pas conscientes de ce que vivent les utilisateurs lorsqu’ils utilisent les systèmes informatiques pour accomplir leur travail quotidien. Avec le temps, cela érode la valeur perçue par les dirigeants d’entreprise envers leur organisation informatique interne. Cela ne veut pas dire que les dirigeants d’entreprise ne comprennent pas (et peut-être même ne compatissent pas) avec la difficulté de surmonter ces défis, mais les entreprises avancent à leur propre rythme et l’organisation doit garder une longueur d’avance pour maintenir son avantage concurrentiel.
Une solution évidente est d’augmenter le financement de la formation et de l’infrastructure en TI et d’embaucher des effectifs supplémentaires en TI; Cependant, de manière générale, ces solutions entrent en conflit avec la tendance à minimiser les dépenses. De plus, il est difficile de prévoir avec précision les besoins budgétaires annuels en formation et effectifs, et difficile à ajuster en cours d’année si ces fonds ne sont pas déjà alloués.
Notre article précédent a mis en lumière quatre avantages à engager un MSP pour fournir des services gérés (MS) afin de relever ces défis. Examinons maintenant plus précisément comment la SEP peut être une bonne solution à ces défis courants; Je vais encadrer cette conversation selon le type de contrat MS pour la rendre plus facile à consommer.
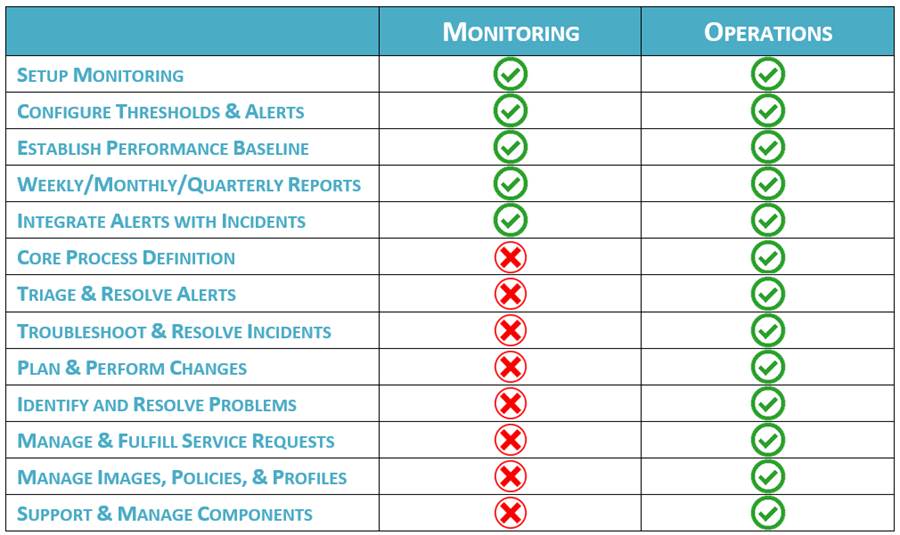
Services gérés pour la surveillance
Pour bénéficier aux TI et à l’entreprise, un MSP peut offrir de la surveillance et de la gestion d’événements aux entreprises qui ont du mal à obtenir une visibilité sur ce que vivent les utilisateurs lors de l’utilisation des systèmes informatiques pour leur travail quotidien, ce qui augmente la probabilité d’identifier les problèmes potentiels avant qu’ils n’aient un impact significatif sur les utilisateurs finaux et/ou de réduire leur impact en les identifiant plus tôt.
Pour offrir ce service, un MSP installera son outil de surveillance dans le paysage informatique du client, et configurera objets/compteurs, services et événements pour l’infrastructure (back-end). Par exemple, les métriques d’infrastructure incluent généralement des métriques traditionnelles de « feu de circulation » telles que la consommation de processeur et de mémoire, l’utilisation de bande passante et la consommation de stockage. Après avoir configuré les métriques, des seuils par défaut seront souvent utilisés, et avec le temps, ces seuils seront ajustés en fonction de ce qui constitue une plage normale de fonctionnement pour ce client. Par la suite, les alertes seront définies selon des seuils finement ajustés, et des ajustements seront effectués pour éliminer les alertes de bruit blanc afin que seules les alertes exploitables subsistent.
Habituellement, les alertes sont classées comme information, avertissement ou erreur. En général, les alertes d’information informent les administrateurs d’événements qui méritent d’être notés mais qui ne justifient pas nécessairement une action; les alertes d’avertissement signalent des événements qui pourraient survenir et justifient une enquête; Les alertes d’erreur informent des événements qui risquent fort fort de déclencher un problème et qui doivent être rapidement réglés. Dans les trois catégories, il est important d’éliminer (ou du moins de minimiser autant que possible) les alertes de bruit blanc afin d’éviter une situation où les alertes sont systématiquement ignorées (de telles alertes indiquent une alerte probable de bruit blanc qui devrait être supprimée ou ajustée pour devenir exploitable). Les alertes de bruit blanc sont souvent traitées en reclassant une alerte (pour ajuster l’importance perçue), en ajustant un seuil d’alerte à une valeur plus significative, ou en supprimant complètement une alerte.
Après avoir configuré la surveillance de l’infrastructure, un bon MSP configurera des événements pour surveiller l’expérience utilisateur finale (je dis « un bon MSP » parce que tous les MSP ne se valent pas). Par exemple, dans une solution Citrix, la durée de connexion de l’utilisateur sera surveillée pour indiquer la durée moyenne qu’un utilisateur doit attendre qu’une session Citrix s’ouvre (c’est-à-dire qu’il soit prêt à utiliser). La surveillance de l’expérience utilisateur implique souvent l’introduction d’une logique de code pour configurer une alerte intelligente; Par exemple, une occurrence d’un événement de « session abandonnée » peut ne pas être préoccupante, mais 20+ cas de ce type en une minute peuvent indiquer un problème important (comme un serveur hors ligne), donc la logique du code sera utilisée pour déclencher une alerte basée sur le nombre de fois où un événement « alertable » se produit dans un délai donné.
De plus, un sondage auprès des utilisateurs finaux peut être distribué pour recueillir les retours subjectifs des utilisateurs finaux concernant leur expérience avec l’utilisation des systèmes informatiques dans leurs tâches quotidiennes. Le sondage doit être court – moins de 10 questions – et consister en des questions à choix multiples (et non des questions libres) afin que les réponses puissent être recueillies et stockées (par exemple) dans une base de données, ce qui facilite la répétition du même sondage à intervalles réguliers (par exemple semestriels) et la comparaison des réponses aux tendances ou schémas spot. (Ferroque Systems MS utilise un sondage à choix multiples efficace de 6 questions conçu pour les environnements Citrix, incluant des réponses à choix multiples organisées pour repérer facilement les tendances mauvaises, neutres ou positives)
At this point, the next step is to configure a systems performance baseline; one technique I have found effective is to set threshold values based upon what constitutes a “known good” user experience. This essentially involves marrying objective metrics to subjective user feedback. To do so, based upon answers from end-user surveys, note if the overall trend reflects a poor, fair, or good user experience. Overlay these trends onto objective infrastructure/user-experience metric values, with the goal of organizing objective metric values into category ranges of poor, fair, and good values so that a range of metric values can be used to indicate a poor, fair, or good user experience. For example, a “poor” metric value range may include CPU and memory greater than 90% (>90%), a “fair” range may be 75-89%, and a “good” range may be less than 74% (<74%). Note that this is an overly simplistic example to illustrate the concept. This exercise should be repeated whenever a user survey is captured, so the baseline is refreshed and maintained over time, with the goal of being able to use objective metric values as a fairly accurate barometer of the likely user experience.
Un autre élément important (mais souvent négligé) est la capacité des rapports à parler le langage de l’entreprise, en adaptant le contenu des rapports pour résonner auprès des dirigeants d’entreprise. Par exemple, un rapport de surveillance traditionnel montre un graphique linéaire du processeur, de la mémoire et d’autres valeurs similaires, mais la plupart des dirigeants d’entreprise ne pourront pas tirer de conclusions significatives à partir de tels rapports (pas plus qu’un administrateur TI ne pourrait tirer des conclusions significatives d’un rapport d’affaires montrant le coût/widget et le nombre de widgets par semaine produits). La clé, c’est le contexte. Ainsi, plutôt que de présenter des graphiques de lignes « feux de circulation » traditionnels, les rapports de surveillance devraient être adaptés pour résonner auprès des dirigeants d’entreprise en indiquant (par exemple) que la consommation de ressources de calcul sur les serveurs hébergeant des applications de la chaîne d’approvisionnement est stable et peut accueillir deux utilisateurs supplémentaires avant que des fonds supplémentaires ne soient nécessaires pour ajouter un serveur supplémentaire, et cela prend environ deux semaines pour acquérir et mettre en place un nouveau serveur. Désormais, la responsable de la chaîne d’approvisionnement peut consulter ses prévisions de ventes de produits pour comprendre si elle doit embaucher plus de personnel, et peut informer l’informatique à l’avance si nécessaire. Encore une fois, c’est un exemple simplifié, mais il illustre le concept de la façon dont des rapports significatifs peuvent permettre une bien meilleure planification et prise de décision.
Jusqu’à présent, je me suis concentré sur les mécanismes de surveillance et de rapports, car c’est un défi que nous avons constaté chez de nombreux clients, mais ce n’est que la moitié de l’équation, car la surveillance devrait être effectuée dans le cadre d’un processus de gestion d’événements clairement défini. Un processus mature de gestion d’événements définit et régit la configuration des outils de surveillance, la création et la gestion de base, la définition et la réponse des alertes, les types et contenus des rapports, l’intégration avec la gestion des incidents et problèmes et le DevOps (pour les réponses automatisées), ainsi que les rôles et responsabilités connexes. La surveillance et le reporting peuvent encore se faire en l’absence d’une gestion d’événements clairement définie, mais c’est beaucoup moins efficace et efficient. Il est hors du cadre de ce billet d’approfondir ces processus, mais je les mentionne ici pour souligner leur importance et offrir un peu de contexte sur leur lien avec la surveillance.
Comme nous pouvons le voir, pour bénéficier aux TI et aux entreprises, un bon MSP fournira une solution comprenant à la fois une solution de suivi et de rapports ainsi qu’un processus global de gestion d’événements, et travaillera avec les clients pour intégrer l’outil et le processus dans l’organisation TI du client en fonction des outils existants du client, les processus, et le niveau de maturité des processus organisationnels. (Ferroque Systems MS utilise un diagramme de flux de travail et des matrices RACI pour intégrer notre outil de surveillance et notre processus de gestion d’événements dans l’organisation informatique de nos clients)
Services gérés pour les opérations
Pour bénéficier aux TI et aux entreprises, les MSP peuvent assumer la responsabilité du soutien opérationnel continu et de la gestion des systèmes dans le cadre des entreprises dont l’organisation informatique manque de personnel, qui ne possède pas encore suffisamment de compétences internes pour une ou plusieurs technologies particulières, et/ou consacre trop de temps à des activités opérationnelles au détriment de la livraison de nouvelles fonctions d’affaires (ou de l’optimisation de celles existantes). En transférant la propriété opérationnelle à un MSP, une organisation TI peut prendre en charge simultanément plus de projets d’affaires et livrer plus rapidement les résultats du projet; C’est-à-dire que les TI peuvent se concentrer sur l’utilisation de leurs technologies pour faire croître l’entreprise tandis que le MSP se concentre sur le maintien de ces technologies.
Pour fournir ce service, un MSP définira et intégrera les processus pour les activités opérationnelles principales telles que la gestion des incidents, la gestion du changement, la gestion des problèmes et la satisfaction des demandes de service (en plus de la surveillance et de la gestion des événements, comme examiné ci-dessus).
En première étape du processus d’intégration, le MSP examinera ces processus clés avec le client, incluant une revue du système de tickets, des mécanismes de gestion des billets, des flux de travail et de la gouvernance des processus, ainsi que des rôles et responsabilités. Un bon MSP fournira son service conformément à un ensemble défini de processus pour insuffler structure et prévisibilité à ses actions quotidiennes. Pour ce faire, un MSP commencera par examiner les processus opérationnels et le flux de travail existants du client, comparativement aux processus opérationnels du MSP, identifiera les points communs, les écarts et les lacunes, et déterminera si ces écarts doivent être conservés et comment combler les lacunes (selon la structure opérationnelle et la maturité des processus du client) ou s’ils doivent être ajustés pour intégrer des éléments du processus correspondant du MSP. Et cela va au-delà des processus fondamentaux ITIL pour inclure aussi d’autres processus opérationnels clés, comme la gestion des images et la transition opérationnelle.
Cela inclura l’examen du support et de la structure informatique du client pour comprendre la meilleure façon d’intégrer les ressources du MSP, ainsi que la révision du système de billetterie et des mécanismes des tickets du client (c’est-à-dire le routage des tickets, la gravité, le statut, etc.) afin de mieux coordonner la mécanique des tickets entre les systèmes de ticketing du client et du MSP. Par exemple, le MSP aura besoin de sa propre file d’attente de tickets afin que les ressources MSP puissent recevoir, créer, gérer, acheminer et rapporter les billets. Certains MSP, dont Ferroque MS, animeront un atelier avec le service d’assistance client pour effectuer un essai général de soumission, de routage et de gestion de tous les types de billets dans le champ d’application afin de valider que l’accès, les permissions et les files d’attente requis ont été provisionnés afin de faciliter la bonne mécanique des tickets conformément aux processus opérationnels définis. C’est une étape cruciale puisque la bonne mécanique des tickets est un ingrédient clé dans la recette d’un service géré de haute qualité; par exemple, il ne serait pas possible de respecter les SLA et les SLT contractuels sans d’abord configurer la logistique appropriée du système de billetterie.
Une fois ces tâches logistiques complétées, l’étape suivante consiste à revoir les rôles et responsabilités inter-équipes spécifiques afin que toutes les personnes de toutes les équipes comprennent les attentes opérationnelles envers elles-mêmes et celles de leurs coéquipiers. Typiquement, une matrice RACI est utilisée pour piloter cet exercice. Cela commence souvent par utiliser une matrice RACI par défaut (basée sur les définitions de processus de cœur par défaut), puis la matrice RACI sera ajustée selon les processus et procédures spécifiques du client. Notez que la définition de RACI n’est généralement pas un événement ponctuel; il se produit plutôt plusieurs fois lorsque (par exemple) de nouveaux serveurs et applications sont ajoutés, et lorsque d’autres changements importants sont apportés à l’environnement de production (cela ne consiste pas à revoir l’ensemble du RACI, seulement la partie qui est pertinente pour la portée du changement).
Au-delà des opérations, un bon MSP rencontrera aussi les chefs de groupe d’affaires du client, afin d’établir (au minimum) une reconnaissance de nom et de comprendre comment ces groupes d’affaires utilisent et interagissent avec les systèmes informatiques. Par exemple, identifier les rôles et responsabilités des groupes d’affaires, les fonctions majeures que chaque rôle accomplit, les systèmes qui permettent ces fonctions, et (ce que j’aime appeler) les « métriques qui comptent » pour ce groupe d’affaires. Cela permettra au MSP d’avoir une compréhension complète de l’utilisation des systèmes informatiques du client et (lorsque possible) d’adapter ses services pour offrir une meilleure valeur à l’entreprise (par exemple, surveiller les « indicateurs qui comptent » et adapter le contenu des rapports de façon à mieux résonner auprès des dirigeants d’entreprise).
En fin de compte, l’objectif est d’intégrer le MSP afin que celui-ci soit autonome dans le soutien et la gestion de l’environnement dans le champ d’application du client; en conséquence, le MSP devrait pouvoir fonctionner comme une extension de l’équipe opérationnelle du client. À ce titre, le client peut transférer la propriété au MSP pour toutes les responsabilités opérationnelles de l’environnement dans le champ d’application. Ce n’est qu’une fois cela accompli que le client peut recentrer ses ressources informatiques internes pour se concentrer sur des initiatives stratégiques d’affaires. Ainsi, il est important que le MSP dispose d’un processus d’intégration bien défini qui permette de se faire le plus rapidement possible afin que le client puisse commencer à tirer le maximum de valeur de son engagement avec MS.
À suivre...
Cet article présente les défis typiques auxquels de nombreuses entreprises font face, puis passe en revue les avantages qu’un MSP peut offrir pour relever ces défis, en mettant l’accent sur la surveillance et les engagements opérationnels. Dans les prochains articles de la série, nous poursuivrons cette discussion en passant en revue les avantages qu’un MSP peut apporter grâce à l’optimisation et aux engagements de transformation, en passant en revue les indicateurs que les clients peuvent utiliser pour comprendre s’ils tirent le plus de valeur d’un engagement MSP, et en expliquant comment les MSP peuvent interpréter les signaux non exprimés pour savoir s’ils font un bon travail.



