
In our previous post on this topic (Part 1), we reviewed the main types of Managed Services Provider (MSP) contracts (monitoring, operational, optimization, transformative), common expectations of MSP’s in today’s economy, and the importance of defining clear expectations as the backbone of a healthy MSP vendor-customer relationship.
The previous post focused on informing of what Managed Services (MS) is and is not, based upon the type of contract, to serve as a reference to highlight the benefits MSPs can provide to the business and to IT. In this post, we will review typical challenges and the benefits MSPs can provide to address these challenges, and in future posts in the series, we will review the indicators customers can use to understand if they are getting the most value from an MSP engagement, and how MSP’s can interpret unspoken signals to understand if they are doing a good job.
Common Challenges in Today’s Economy
Let’s start by highlighting a few common challenges typically faced by many organizations. In today’s economy, most decisions are based upon a financial justification wherein a project’s outcomes are expected to have direct line-of-sight to increasing revenue and/or decreasing expenses; this makes it very difficult for IT to fund infrastructure projects, such as a wholesale upgrade of Active Directory (AD) or a widespread upgrade of server operating systems (OS). In our previous post, we touched upon chronic understaffing within IT, wherein too few IT resources are available to staff business projects, which often compels business groups to act independently, which often inadvertently produces myopic outcomes. Sometimes a company’s IT organization does not possess the appropriate in-house skillsets for newer technologies; combined with lower IT funding (for training, infrastructure upgrades, etc.), this often results in older technologies remaining in-place beyond their intended lifetime. Many companies monitor the IT infrastructure but do not properly monitor the end-user experience, such that in too many cases the back-end alerts do not indicate any issues are occurring but end-users are experiencing performance degradation or possibly service disruption, without IT being aware until users report issues.
These challenges influence business leaders’ perception that IT is unable to meet business needs in a timely fashion, that IT does not provide accurate solutions, and/or that IT is not aware of what users experience while using IT systems to do their daily jobs. Over time, this erodes business leaders’ perceived value of their in-house IT organization. This is not to say that business leaders do not understand (and perhaps even empathize with) the difficulty of overcoming these challenges, but business moves at its own pace and the organization must stay ahead of the curve to maintain its competitive advantage.
One obvious solution is to increase funding for IT training and infrastructure and hire additional IT headcount; however, broadly speaking, these solutions conflict with the inclination to minimize expenses. As well, it is challenging to accurately forecast annual budget needs around training and headcount, and difficult to adjust mid-year if those funds are not already allocated.
Our previous post highlighted four benefits of engaging an MSP to deliver managed services (MS) to address these challenges. Let’s now look more specifically at how MS can be a good solution to these common challenges; I will frame this conversation by MS contract type to make it easier to consume.
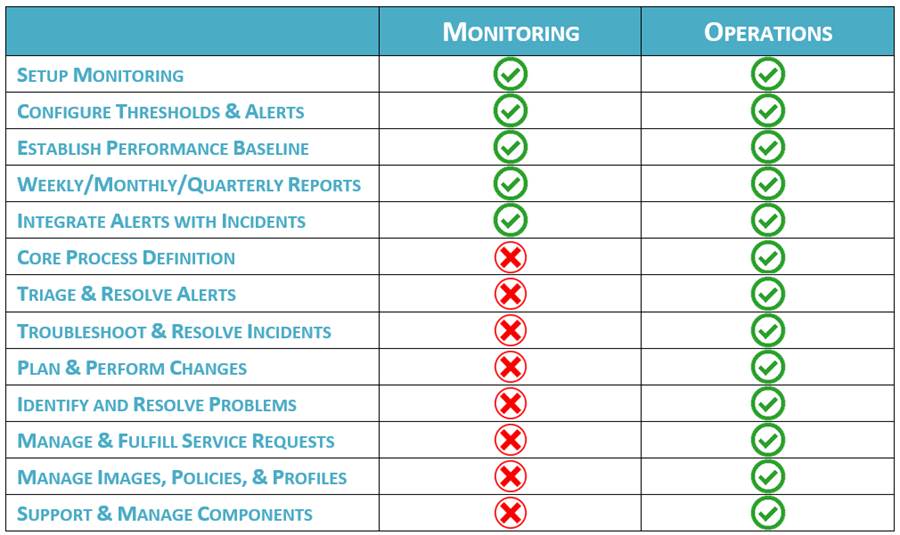
Managed Services for Monitoring
To benefit IT and the business, an MSP can provide monitoring and event management to companies who are having difficulty getting visibility into what users experience while using IT systems to do their daily jobs, which increases the probability of identifying potential issues before they significantly impact end-users and/or of lowering the impact by identifying issues earlier.
To deliver this service, an MSP will set up their monitoring tool within the customer’s IT landscape, and configure objects/counters, services, and events for the infrastructure (back-end). For example, infrastructure metrics typically include traditional “traffic light” metrics such as CPU and memory consumption, bandwidth usage, and storage consumption. After configuring the metrics, default threshold values will often be used, and over time these thresholds will be fine-tuned based upon what constitutes a normal operating range for that customer. Thereafter, alerts will be defined based upon fine-tuned thresholds, and adjustments will be made to eliminate white noise alerts so that only actionable alerts remain.
Typically, alerts will be categorized as information, warning, or error. In general, information alerts inform administrators of events that are worth noting but do not necessarily warrant action; warning alerts inform of events that signal a potential issue could occur and warrant investigative action; error alerts inform of events that will very likely trigger an issue and should be quickly addressed. In all three categories, it is important for white noise alerts to be eliminated (or at least minimized as much as possible) to avoid a situation wherein alerts are routinely ignored (such alerts indicate a probable white noise alert that should be removed or adjusted to become actionable). White noise alerts are often addressed by re-categorizing an alert (to adjust perceived importance), adjusting an alert threshold to a more meaningful value, or removing an alert altogether.
After configuring infrastructure monitoring, a good MSP will configure events to monitor the end-user experience (I say “a good MSP” because not all MSPs are created equal). For example, in a Citrix solution, user logon duration will be monitored to note the average length of time a user must wait for a Citrix session to open (i.e. be ready to use). User experience monitoring often involves introducing code logic to configure an intelligent alert; for example, one occurrence of a “dropped session” event may not be concerning, but 20+ such instances in one minute may indicate a significant issue (such as a server going offline), so code logic will be used to trigger an alert based upon the number of times an “alertable” event occurs within a specific timeframe.
As well, an end-user survey may be distributed to capture end-users’ subjective feedback regarding their experience with using IT systems to do their daily jobs. The survey should be short – less than 10 questions – and should consist of multiple-choice questions (not freeform questions) so answers can be captured and stored in (for example) a database, which facilitates repeating the same survey in regular intervals (e.g. semi-annual) and comparing answers to spot trends/patterns. (Ferroque Systems MS uses an effective 6-question multiple-choice survey designed for Citrix environments, including multiple-choice answers organized to easily spot poor, neutral, or positive trends)
At this point, the next step is to configure a systems performance baseline; one technique I have found effective is to set threshold values based upon what constitutes a “known good” user experience. This essentially involves marrying objective metrics to subjective user feedback. To do so, based upon answers from end-user surveys, note if the overall trend reflects a poor, fair, or good user experience. Overlay these trends onto objective infrastructure/user-experience metric values, with the goal of organizing objective metric values into category ranges of poor, fair, and good values so that a range of metric values can be used to indicate a poor, fair, or good user experience. For example, a “poor” metric value range may include CPU and memory greater than 90% (>90%), a “fair” range may be 75-89%, and a “good” range may be less than 74% (<74%). Note that this is an overly simplistic example to illustrate the concept. This exercise should be repeated whenever a user survey is captured, so the baseline is refreshed and maintained over time, with the goal of being able to use objective metric values as a fairly accurate barometer of the likely user experience.
Another important (but often overlooked) element is the ability for reports to speak the language of the business, by tailoring report content to resonate with business leaders. For example, a traditional monitoring report shows a line graph of CPU, memory, and similar such values, but most business leaders will not be able to draw meaningful conclusions from such reports (any more than an IT administrator could draw meaningful conclusions from a business report showing the cost/widget and how many widgets/week were produced). The key is context. Thus, rather than show traditional “traffic light” line graphs, monitoring reports should be tailored to resonate with business leaders by (for example) indicating that compute resource consumption on servers that host Supply Chain applications is holding steady and can accommodate two more users before additional funds will be needed to add one more server, and it takes approx. two weeks to procure and stand up a new server. Now, the Supply Chain business leader can refer to her product sales forecast to understand if she may need to hire more staff, and can inform IT in advance if necessary. Again, this is an over-simplified example, but it illustrates the concept of how meaningful reports can enable much better planning and decision-making.
Thus far, I have focused on the monitoring and reporting mechanics since this is a challenge we have seen plague many customers, but that is only half the equation, as monitoring should be performed in the context of a clearly-defined event management process. A mature event management process defines and governs monitoring tool configuration, baseline creation and management, alert definition and response, report types and content, integration with incident and problem management and DevOps (for automated responses), and related roles and responsibilities. Monitoring and reporting can still happen in the absence of clearly-defined event management, but it is much less effective and efficient. It is beyond the scope of this post to deep-dive into these processes, but I mention them here to highlight their importance and offer a bit of context into how they are linked to monitoring.
As we can see, to benefit IT and the business a good MSP will provide a solution that consists of both a monitoring and reporting solution as well as an overall event management process, and will work with customers to integrate the tool(s) and process into the customer’s IT organization based upon the customer’s existing tools, processes, and level of organizational process maturity. (Ferroque Systems MS uses a workflow diagram and RACI matrices to incorporate our monitoring tool and event management process into our customers’ IT organization)
Managed Services for Operations
To benefit IT and the business, MSP can take responsibility for ongoing operational support and management of in-scope systems for companies whose IT organization is understaffed, does not yet have sufficient in-house skills for a particular technology(ies), and/or spends too much time on operational activities at the expense of delivering new (or optimizing existing) business functions. By offloading operational ownership to an MSP, an IT organization can take on more business projects simultaneously and be able to more quickly deliver project outcomes; i.e. IT can focus on leveraging its technologies to grow the business while the MSP focuses on maintaining these technologies.
To deliver this service, an MSP will define and integrate processes for core operational activities such as incident management, change management, problem management, and service request fulfillment (in addition to monitoring and event management, as reviewed above).
As a first step in the onboarding process, the MSP will review these core processes with the customer, including a review of the ticketing system, ticket management mechanics, process workflows and governance, and roles and responsibilities. A good MSP will deliver its service in accordance with a defined set of processes to inject structure and predictability into their daily actions. To do so, an MSP will start by reviewing the customer’s existing operational processes and workflow, compared to the MSP’s operational processes, identify commonalities, variances, and gaps, and determine if those variances should be retained and how to address any gaps (based upon the customer’s operational structure and process maturity) or if they should be adjusted to incorporate elements from the MSP’s corresponding process. And this extends beyond just core ITIL processes to also include other key operational processes, such as for image management and operational transition.
This will include reviewing the customer’s Support and IT structure to understand how best to onboard the MSP’s resources, as well as reviewing the customer’s ticketing system and ticket mechanics (i.e. ticket routing, severity, status, etc.) to understand how best to coordinate ticket mechanics between the customer and MSP ticketing systems. For example, the MSP will need its own ticket queue so MSP resources can receive, create, manage, route, and report on tickets. Some MSP’s, including Ferroque MS, will lead a workshop with the customer’s Helpdesk to conduct a dry run of submitting, routing, and managing all in-scope ticket types to validate the requisite access, permissions, and queues have been provisioned to facilitate proper ticket mechanics in accordance with defined operational processes. This is a crucial step since proper ticket mechanics is a key ingredient in the recipe of a high-quality managed service; for example, it would not be possible to uphold contractual SLA’s and SLT’s without first configuring the proper ticketing system logistics.
Once these logistical items have been completed, the next step is to review specific cross-team roles and responsibilities so all persons on all teams understand the operational expectations of themselves and of their teammates. Typically, a RACI matrix is used to drive this exercise. This will often start by using a default RACI matrix (based upon default core process definitions) and then the RACI matrix will be fine-tuned according to the customer’s specific processes and procedures. Note that RACI definition is usually not a one-time event; rather, it usually occurs multiple times when (for example) new servers and new applications are added, and when other significant changes are made to the production environment (this does not entail reviewing the entire RACI, just the portion that is germane to the scope of the change).
Beyond just operations, a good MSP will also meet with the customer’s business group leaders, to establish (at minimum) name recognition and to understand how these business groups use and interact with the IT systems. For example, to identify business group roles and responsibilities, the major functions each role performs, the systems that enable those functions, and (what I like to call) the “metrics that matter” for that business group. This will allow the MSP to have a comprehensive understanding of how the customer’s IT systems are used and (when possible) to tailor its services to provide better value to the business (e.g. to monitor the “metrics that matter” and to tailor report content in a way that better resonates with business leaders).
Ultimately, the goal is to onboard the MSP so that the MSP can be self-sufficient in supporting and managing the customer’s in-scope environment; as a result, the MSP should be able to function as an extension of the customer’s operational team. In this capacity, the customer can offload ownership to the MSP for all operational responsibilities for the in-scope environment. Only once this has been achieved is the customer able to refocus its internal IT resources to focus on strategic business initiatives. Thus, it’s important for the MSP to have a well-defined onboarding process that allows onboarding to be completed as quickly as possible so the customer can begin to realize maximum value from its MS engagement.
To be continued…
This post outlines typical challenges that many companies experience, and proceeds to review the benefits an MSP can provide to address these challenges, focusing on monitoring and operational engagements. In ensuing posts in the series, we will continue this discussion by reviewing benefits an MSP can provide via optimization and transformation engagements, review the indicators customers can use to understand if they are getting the most value from an MSP engagement, and how MSP’s can interpret unspoken signals to understand if they are doing a good job.



