
Introduction and Background
Citrix ADCs (formerly NetScaler) use an in-built MaxMind IP geodatabase which is great for conventional use, however, there are certainly numerous third-party databases available that are updated regularly, and contain more granular details.
A customer wanted to migrate over their existing NetAcuity geolocation database into the Citrix ADC with more entries than I had fingers, so data entry was out of the question.
Solution
Python. Let’s go another step further and build a script that is relatively straightforward and can adjust to various scenarios allowing us to kick back and relax.
Before We Get Going…
There are a few items for us to get out of the way for some context, references, as well as tips.
Terms and Uses for Geolocation Databases
This article isn’t going to cover what a geolocation database is, but this Citrix Doc can assist there if need be. Below are some terms and uses for geolocation databases on a Citrix ADC.
- Geo-location: The Citrix ADC appliance can get the user’s location details like continent, country, city, latitude and longitude, etc. from their public IP address. The location details are sourced from a geolocation database that holds various CIDR blocks and their associated information. Some geolocation databases include other granular details such as ZIP code, Internet connection type, and more.
- Static Proximity: An option in GSLB configurations that uses a geolocation database to determine which GSLB service to direct client requests, based on the proximity to the GSLB service (closer = better).
- Geo-blocking: Blocking access based upon a user’s location (or rather, based on IP).
- Geo-fencing: Triggering an event depending on if the user is in a predefined location.
Wildcard Use in Geolocation Expressions
As referenced here: https://www.irangers.com/citrix-netscaler-geoip-broken/. Policies with wildcards need to have this command explicitly enabled. Considering wildcards are fairly important to mapping out geolocation details, it is necessary to ensure this function is enabled on the appliance, as by default it is not. The following command will achieve this for you:
set locationParameter -matchWildcardtoany YES
Built-in Citrix Database Formats
This script was engineered to assist in converting non-Citrix native geolocation databases (Specifically NetAcuity, albeit one may opt to reverse engineer the logic and adapt it to other databases). The Citrix geolocation database format can be found here.
Onto The Script…
The goal here is to take a geolocation database which which isn’t immediately compatible with the Citrix geolocation formats, and parse out the vital data and transform it into a useable format that can be imported onto the appliance. The Python script will be provided at the end of this guide.
How the Script Works
The script takes raw data, and once a delimiter is specified then specific fields can be chosen to match the default Netscaler geolocation db format.
The first 2 fields MUST be in dotted decimal format with the first entry being Start and the second entry being End of scope. Any line that doesn’t begin with 2 IP addresses are skipped over.
Example of DB entries from a non-native format:
2.16.224.0;2.16.224.255;bra;sp;sao paulo;broadband;76009;-23.52;-46.63;01101-080;76;726;4162;7;br;1;?;99;85;80;30;-300;n;america/sao_paulo;
2.17.128.0;2.17.159.255;usa;ca;los angeles;broadband;803;34.01;-118.26;90011;840;5;113;6;us;1;213;99;90;90;30;-700;y;america/los_angeles;
Pre-requisites
If you’re using Linux or Mac then run the command below to be able to run this script as an executable. It checks if you have python3 installed as the default python interpreter then adds the shebang into the script and copies the script file into a .sh file. The script can be executed with ./geo rather than “python geo.py” a whopping saving of 1 second!
The same one-liner can be used on the ADC to achieve the same goal, which may be particularly useful for some deployments.
Windows users should have python3 installed to execute the script.
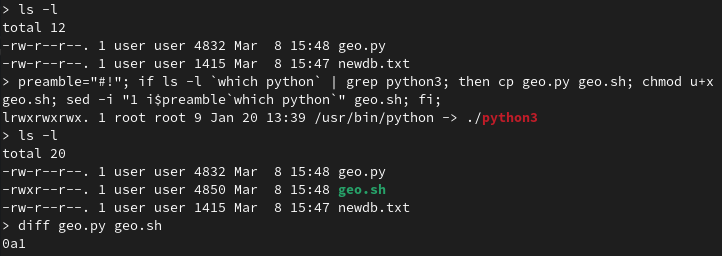
preamble="#!"; if ls -l `which python` | grep python3; then cp geo.py geo.sh; chmod u+x geo.sh; sed -i "1 i$preamble`which python`" geo.sh; fi;
Step 1
It’s easier to have the working files such as the script and the raw geolocation database file in a single directory so begin there. View the database file to view what the delimiter will be. In this instance it will be a semicolon ;.
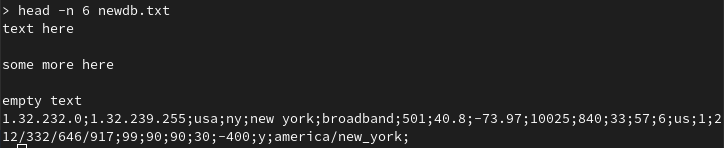
Step 2
Run the script with either command below:
./geo.sh [db-filename] python geo.py [db-filename]
The default value for delimiter is a semicolon [;] so either hit enter to continue or enter a different value.
After, the first line in the database is read, so work through the fields and input the numbers that correlate to the values. If no value matches then just press enter to continue.
After the values are finished, verify that everything looks good and proceed to create the database.
NOTE: The original geolocation database won’t be overwritten, but a new file will be created with “_processed” appended to it.
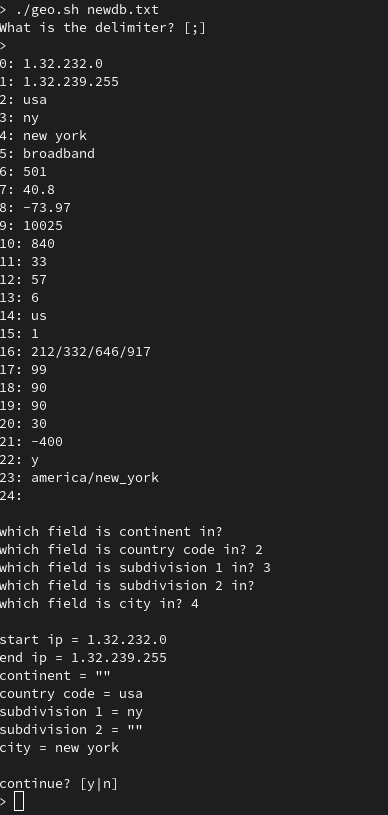
Step 3
Depending on the size of the database, the script can take a few minutes to run. However, once completed the number of lines processed and lines skipped will be printed to the screen.
This demo only uses 10 lines however the actual database I processed for the customer had well over a million lines.
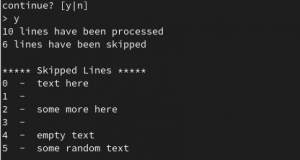
Step 4
We can see the newdb.txt_processed file created has been formatted into the style we wanted and can easily be installed onto the ADC.
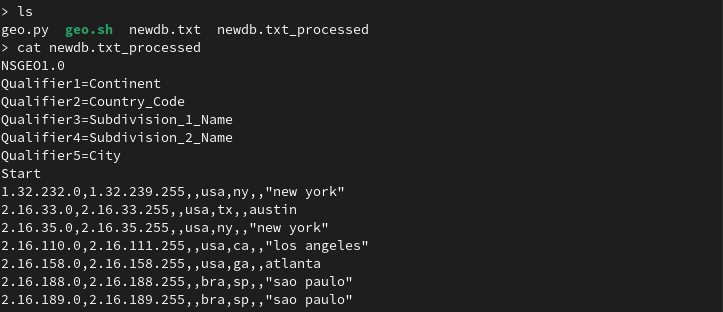
Step 5
Transfer over the processed database in /var/netscaler/locdb/ using either winscp under ftp mode or scp.

Step 6
The database can be imported either through the gui or command line. Through the gui, access AppExpert > Location > Static Databases > Static Databases (IPv4) and add the file in /var/netscaler/locdb.
The NetScaler CLI command-line approach is more informative:
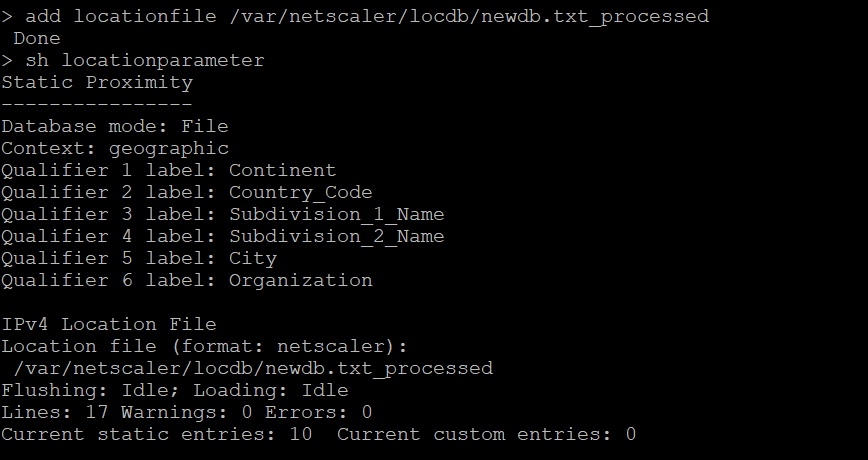
add locationfile /var/netscaler/locdb/newdb.txt_processed
This NetScaler CLI command shows more information about the database that the ADC can view. Lines shows the total lines including the NSGEO1.0 preamble while the next 10 entries are correctly read.
sh locationparameter
(Optional)
The nsmap command (from NetScaler CLI drop to shell) can be used as a dry run to test if an entry in the new database was working. Throw a dart anywhere with the keyboard and see if it works.
nsmap -d -t

Example
For this tutorial, I’ll be using a load balancer named vs-example and a responder policy. However, your implementation might be for GSLB and static proximity, which we won’t get into here. This responder policy will use the geodb to prevent access from any IP matching the Brazil country code.

add responder action block_example respondwith "\"The IP address you are connecting from (\"+CLIENT.IP.SRC+\") is not authorized to access our systems.\"" add responder policy block_example_pol "CLIENT.IP.SRC.MATCHES_LOCATION(\"*.bra.*.*.*\")" block_example bind lb vserver vs-example -policyName block_example_pol -priority 1 -type REQUEST
Kick the tires and test it out in your own deployment to confirm expected functionality.
The Script
Save this code as geo.py. As a reminder, this was developed with a particular geodb in mind (NetAcuity) so it may need some restructuring for other geodatabase formats.
import sys
import os
import re
try:
_filename = sys.argv[1]
_raw_list = {}
_skipped = {}
check = {
"start ip": 0,
"end ip": 1,
"continent": 2,
"country code": 3,
"subdivision 1": 4,
"subdivision 2": 5,
"city": 6
}
check2 = ["continent", "country code", "subdivision 1", "subdivision 2", "city"]
def read_file_ipv4(_read):
# break raw file into fields
with open(_filename) as fn:
i = 0
j = 0
for line in fn:
if re.match('[0-9]+.[0-9]+.[0-9]+.[0-9]+', line):
_raw_list[i] = line.split(_delimiter)
i += 1
if _read == 1:
break
else:
_skipped[j] = line
j += 1
def confirm():
# confirm results
print()
print(f"start ip = {_raw_list[0][check.get('start ip')]} ")
print(f"end ip = {_raw_list[0][check.get('end ip')]} ")
for i in check2:
try:
print(f"{i} = {_raw_list[0][check.get(i)]}")
except:
print(f"{i} = \"\"")
def helper(i, list_index):
switcher = {
2: check.get("continent"),
3: check.get("country code"),
4: check.get("subdivision 1"),
5: check.get("subdivision 2"),
6: check.get("city")
}
if type(switcher.get(list_index)) == str:
return ""
else:
if ' ' in _raw_list[i][switcher.get(list_index)]:
return f'\"{_raw_list[i][switcher.get(list_index)]}\"'
else:
return _raw_list[i][switcher.get(list_index)]
def write_file():
# writing results to file
with open("{}_processed".format(_filename), 'w') as fout:
fout.write("NSGEO1.0\n")
fout.write("Qualifier1=Continent\n")
fout.write("Qualifier2=Country_Code\n")
fout.write("Qualifier3=Subdivision_1_Name\n")
fout.write("Qualifier4=Subdivision_2_Name\n")
fout.write("Qualifier5=City\n")
fout.write("Start\n")
for i in range(0, len(_raw_list.keys())):
fout.write("{},{},{},{},{},{},{}".format(
_raw_list[i][0], # start ip
_raw_list[i][1], # end ip
helper(i, 2), # continent
helper(i, 3), # country code
helper(i, 4), # subdivision 1
helper(i, 5), # subdivision 2
helper(i, 6), # city
))
fout.write("\n")
i += 1
print("{} lines have been processed".format(i))
print("{} lines have been skipped".format(len(_skipped.keys())))
print(f"\n{'*' * 5} Skipped Lines {'*' * 5}")
for skip in range(len(_skipped.keys())):
print(skip, " - ", _skipped[skip], end="")
if __name__ == "__main__":
if not os.path.isfile(_filename):
print("{} does not exist. Exiting program.".format(_filename))
print(f"\nUsage:\n\t{sys.argv[0]} [db-filename]")
sys.exit()
_delimiter = input("What is the delimiter? [;] \n> ") or ";"
read_file_ipv4(1)
for i in range(len(_raw_list[0])):
print(f"{i}: {_raw_list[0][i]}")
for j in check2:
try:
value = int(input(f"which field is {j} in? "))
except ValueError:
value = " "
check[j] = value
confirm()
read_file_ipv4(0)
answer = input("\ncontinue? [y|n]\n> ")
write_file() if answer.lower() == "y" else sys.exit(1)
except IndexError:
print("Missing file. Exiting program\n")
print("This program takes in the filename and performs operations and outputs filename_processed")
print(f"Usage:\n\tpython {sys.argv[0]} [db-filename]")
sys.exit(1)
Conclusion
Hopefully, this script will be useful for administrators who need to deal with non-native geolocation databases on Citrix ADC. It is a manual task and some deployments may warrant either automated distribution of the converted database to other Citrix ADCs in the GSLB mesh, or automatically pull the geodb file and convert it on a scheduled basis. This could be handled by administrators manually loading the geodb onto a share with a scheduled task that checks for new databases at certain intervals, or if the geolocation provider supports it, making API calls with a clientID and secret key to retrieve the database periodically (if the geolocation vendor has such support).
As time permits, I will build out some automation logic and follow up in another post.
Closing Tip 1: Those using GSLB Static Proximity; EDNS0\ECS should probably be enabled on your GSLB vServers as discussed here in order to enable Citrix ADC to determine the client’s true IP, and not that of the client’s local DNS server when requests are made to GSLB. This is an important consideration on the Internet with the prevalence of recursive DNS. And if the client’s DNS server is not truly local to the client (think of all those “DNS as a Service” platforms consumers tend to use), the results will likely be skewed and return a client IP which is not truly indicative of the end-users real location, rather that of the DNS server.
Closing Tip 2: If using geolocation details in expression policies such as responder or DNS Views, etc. in order for Citrix ADC to leverage the actual client IP when ECS is enabled, the expression “CLIENT.IP.SRC.MATCHES_LOCATION” may need to be changed to “DNS.REQ.OPT.ECS.IP.MATCHES_LOCATION”. This an important consideration when building policy-based DNS logic on Citrix ADC which will be covered in another Ferroque article this year, even on internal networks, when DNS recursion is enabled on DNS servers.



